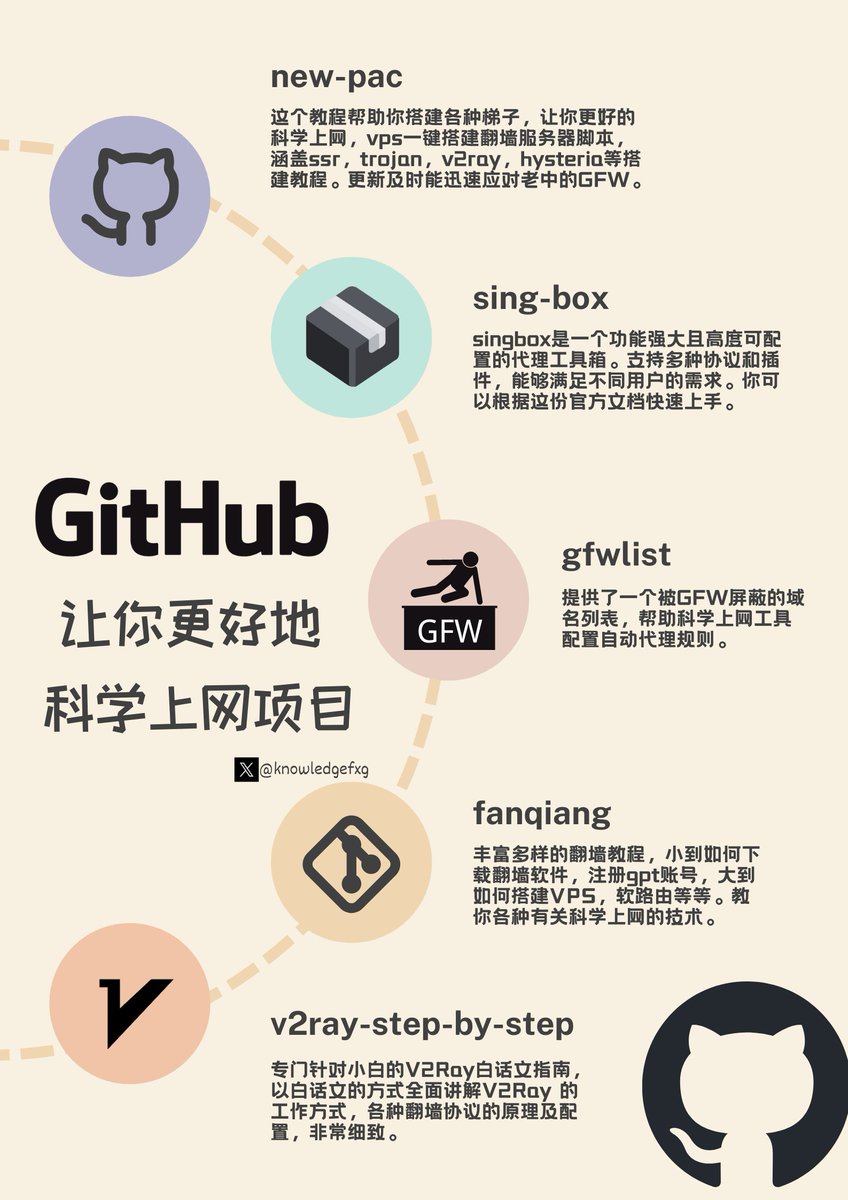
使用SAC(matlab+simulink)深度强化学习,遇到很神奇的事情
使用SAC(matlab+simulink)强化学习,遇到很神奇的事情
1. 问题描述
使用SAC(matlab+simulink)强化学习,遇到很神奇的事情,就是训练过程中,训练的reward会突然出现负值,然后过很久又恢复正值,或者是一直出现最高值,然后再反弹回来。这是什么原因呢?可能是学习参数没写好吧。
这是我最难绷的一次图片,我感觉持续故障时间是最久的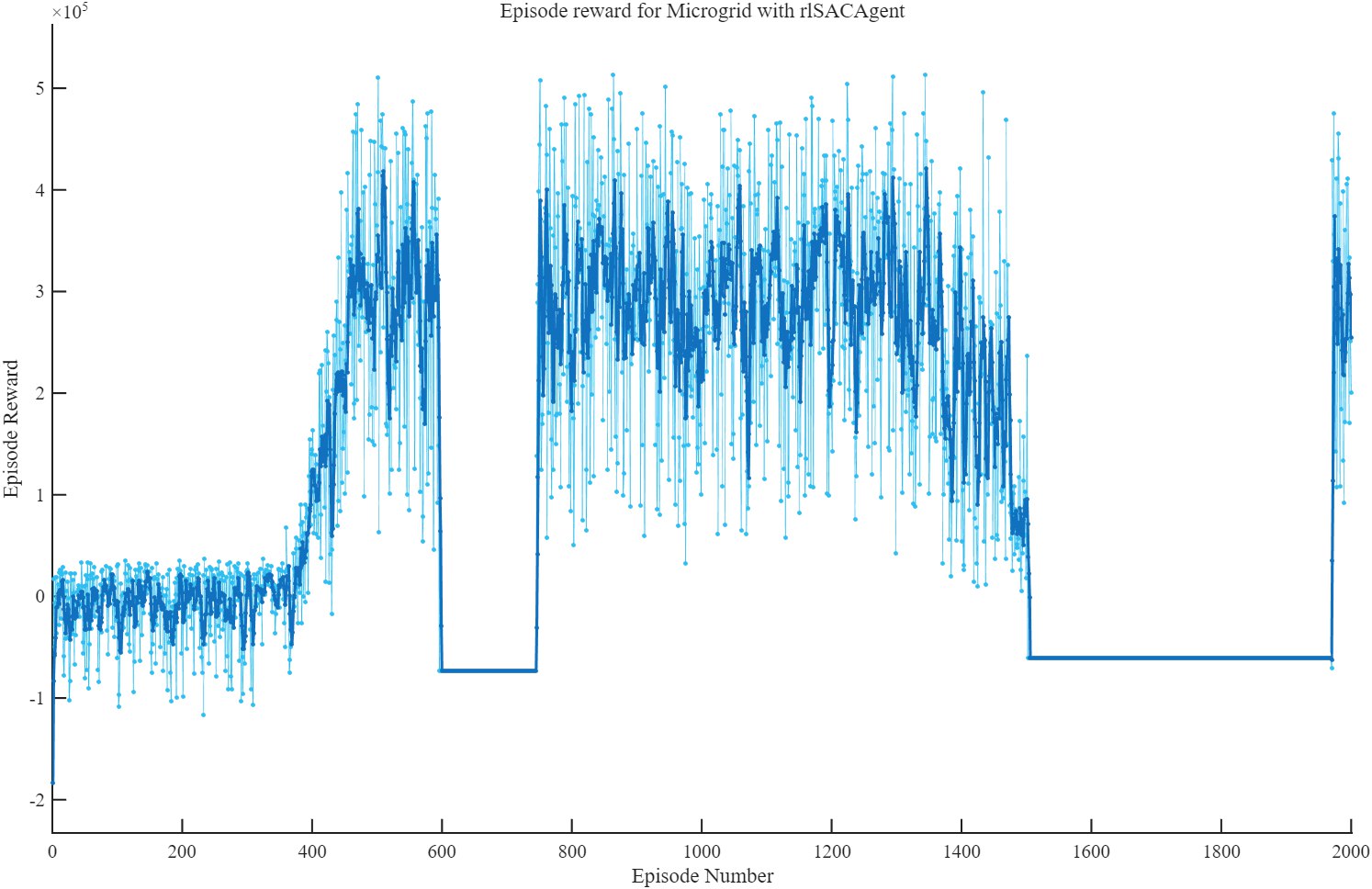
2. 尝试解决方案
Gemini的看法
1 | 根据您提供的“强化学习训练监视器”截图,图中的现象**更可能是强化学习训练过程中的常见问题,而不是MATLAB 2025a或Simulink本身的软件错误(Bug)**。 |
怎么看都是软件bug吧
3.现在的状态
修改了超参数
现在的运行似乎没有明显问题
拭目以待吧
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 twj0-blog!
相关推荐
2025-10-05
matlab深度强化学习何意味?
episode和奖励 图片差别在学校跑的图形 (50个训练集) 在家里跑的图形 (60个训练集) 明明是一样的代码和模型,看来还是不够鲁棒性吗? 反正设计的1000个episode,希望明天早上起床可以看到好东西。 不够其实我已经跑出来了一些图形了,是电池在电网的表现 (viz_Battery_Performance_Analysis_20251003_063134) 国庆节假期结束就要面见导师了,争取明天写出初稿。 没想到二十多天过去了还是缓慢前进。不过也快了,吗?(雾 想问为什么不用python + vibe coding ? 因为matlab + simulink 也是 vibe 来的(bushi

2025-10-23
matlab2025b移除了对sps的支持
mathworks 官方社区图片链接 Gemini短评:MATLAB R2025b: Simscape Electrical 更新,移除“专业电力系统”模块在 MATLAB R2025b 版本中,MathWorks 对 Simscape Electrical 进行了重要更新,其中最引人注目的变化是移除了“专业电力系统”(Specialized Power Systems,简称 SPS)模块库。这一变化意味着之前依赖 SPS 模块进行电力系统建模和仿真的用户,需要将模型迁移至使用标准的 Simscape Electrical 模块。 对于许多用户来说,这一变化带来了如何更新现有模型以及未来如何进行电力系统仿真的疑问。为了帮助用户平稳过渡,MathWorks 提供了名为 spsConversionAssistant 的转换助手工具。 迁移路径:使用 spsConversionAssistant 和 Simscape Electrical当用户在 R2025b 中打开一个包含旧的 SPS 模块的模型时,系统会提示这些模块已被移除,并建议使用 spsConversionAssistan...
评论